作为上海科技大学“智能感知与人机协同”教育部重点实验室的核心研究方向之一,信息学院视觉与数据智能中心 ( VDI Center)长期致力于机器视觉、大数据、人工智能方向的前沿原创科研研究。近期,中心教授团队围绕人工智能领域产出多项科研成果,并被AAAI 年会(AAAI Conference on Artificial Intelligence, AAAI 2023)接收录用。AAAI年会是中国计算机学会推荐的CCF-A类人工智能领域学术会议。
FusionPose,一种新的基于单台激光雷达相机设计的大规模场景3D-MPE方法
大型户外场景室外三维多人姿态估计(3D-MPE)是人类运动理解的一项重要技术,可为许多下游的现实世界应用带来便利,如动作识别、人机协作、服务型机器人等。为提高对场景更细粒度的理解能力,通常会同时利用相机和激光雷达来估计行人的3D姿态。但现有方法直接将多模态特征叠加在一起,没有利用时间信息和几何监督,导致在处理挑战性姿势(如运动)时的表现不佳。为解决上述问题,马月昕课题组提出了FusionPose,一种新的基于单台激光雷达相机设计的大规模场景3D-MPE方法。扩展实验表明,该方法在新收集的数据集LiCamPose和其他相关的开放数据集上实现了较先进的性能。该成果以题为“Weakly Supervised 3D Multi-person Pose Estimation for Large-scale Scenes based on Monocular Camera and Single LiDAR”发表。信息学院研二学生丛佩珊和大四学生许艺腾为论文的共同第一作者,马月昕助理教授为通讯作者。
论文链接:https://arxiv.org/abs/2211.16951
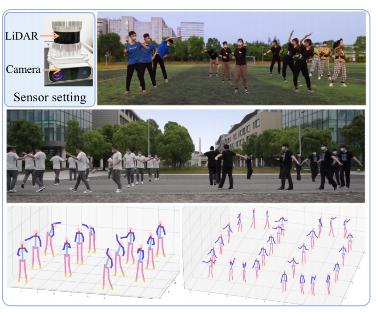
图|传感器设置及算法结果可视化
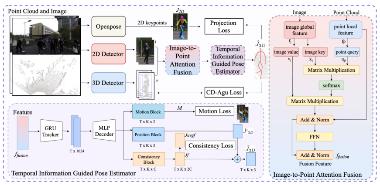
图|算法流程图
CL3D,一种基于无监督的跨域跨激光雷达传感器的三维物体检测算法
基于激光雷达点云的三维物体检测是大场景三维感知的一项重要的任务。目前的域迁移算法很难解决同时跨域和跨传感器的问题,马月昕课题组提出了一种基于无监督的跨域跨激光雷达传感器的三维物体检测算法CL3D:通过挖掘空间中的几何特征和时序上的动态信息,将跨域跨传感器的数据在特征空间进行对齐操作,在新数据没有任何标注数据的情况下依旧保持算法较好的性能表现。CL3D还设计了基于原型表示的伪标签筛选策略,通过一种宽松的约束机制缓解了在训练前期错误标签所带来的误导。相关研究在自动驾驶数据集如Waymo、nuScenes等上进行了实验测试,均取得了较好的性能表现。
该成果题为“CL3D: Unsupervised Domain Adaptation for Cross-LiDAR 3D Detection”。信息学院研二学生彭玺东为该项科研成果的第一作者,马月昕助理教授为通讯作者。
论文链接:https://arxiv.org/abs/2212.00244
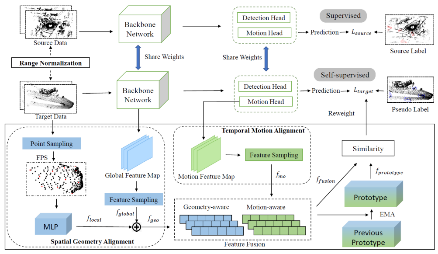
图|算法流程图
HybridCap,一种复杂人体运动通过惯性辅助的单目捕捉算法
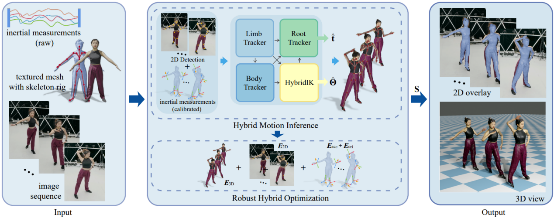
单目三维人体运动捕捉(mocap)对于许多应用有着重要的价值,但使用单个摄像头往往难以处理不同身体部位的遮挡问题,只能捕捉相对简单的运动。许岚课题组提出了一种轻量级的混合式动捕技术,它利用仅有的4个惯性测量单元(IMUs)辅助摄像头,构建了一个学习-优化的框架。该工作还提出一种结合惯性反馈和视觉线索的混合优化方案,以提高追踪精度。在各种数据集上的广泛实验表明,该技术能够鲁棒地处理从健身动作到拉丁舞等具有挑战性的运动,达到每秒60帧的实时性能,并在3DPW,AIST++, 和HCM等公开数据集上取得了较高的准确度。相关成果题为“HybridCap: Inertia-aid Monocular Capture of Challenging Human Motions”,信息学院2020级研究生梁瀚为第一作者,许岚助理教授为通讯作者。
论文链接:https://arxiv.org/abs/2203.09287

图|传感器设置及部分算法结果可视化
图|算法流程图
CCQ: 通过建模跨类查询从多个部分标注的数据集中学习分割多器官和肿瘤
三维CT图像的多器官和肿瘤分割是许多临床应用的基础。基于深度学习的多器官和肿瘤分割依赖大规模完整标注的数据集进行训练,然而现有的大部分数据集都只标注了部分或单个器官,导致不同的数据集无法被充分利用。杨思蓓课题组提出利用多个部分标注的单器官和肿瘤数据集进行联合训练,以实现多器官和肿瘤分割。同时创新提出了跨类别查询网络CCQ,自动学习不同类别的判别性语义概念和表达,并利用该概念捕获不同器官和肿瘤之间的先验关系, 实现充分利用部分标注的医学图像数据集进行多器官分割。实验表明,该方法在开放的七个器官和肿瘤分割的数据集上实现了较优的性能,大幅度提升了多器官分割的准确性。该成果题为“CCQ: Cross-Class Query Network for Partially Labeled Organ Segmentation”。信息学院2020级项目型研究生刘旭阳为论文的第一作者,杨思蓓助理教授为通讯作者。
论文链接:https://github.com/Yang-007/CCQ/blob/main/CCQ.pdf
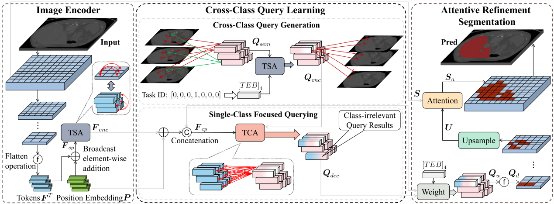
图|跨类别查询网络CCQ示意图
IKOL:基于高斯-牛顿微分的逆向动力学三维人体姿势和形状估计
三维人体参数化模型估计在视频分析、摄像头监控、人机交互、虚拟现实增强现实等领域得到广泛应用。单目三维人体参数化模型估计旨在从单张图像中估计出表示人体姿态与外形的参数化模型,现有基于优化的方法和基于回归的方法都无法满足实际需求。石野课题组提出了IKOL,设计了逆向动力学优化层的网络结构用于三维人体姿势和形状估计。该方法在人体姿态估计榜单3DPW和3DHP上等相关的开放数据集上实现了较优的性能。相关成果题为“IKOL: Inverse kinematics optimization layer for 3D human pose and shape estimation via Gauss-Newton differentiation”。信息学院2019级博士生张钜泽为论文的第一作者,石野助理教授和汪婧雅助理教授为共同通讯作者。
原文链接:https://arxiv.org/pdf/2302.01058.pdf
原文代码链接:https://github.com/Juzezhang/IKOL

图|三维人体参数化模型估计示例
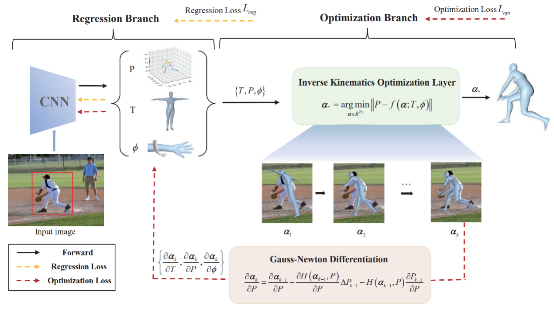
图|IKOL整体算法流程图
CALIP,一种基于注意力机制增强CLIP零样本图片分类的无训练参数算法
对比性语言-图像预训练(CLIP)模型已显示出具有良好零样本性能的视觉表示学习。为进一步提高其下游准确性,现有方法在CLIP之上提出可学习的额外模块,并通过少样本训练集对其进行微调。然而,由此产生的额外训练成本和数据要求严重影响了模型部署和知识传递的效率。何旭明课题组与上海人工智能实验室合作提出了一种无训练参数的增强方法:CALIP,通过一个无参数的注意力模块来提高CLIP的零样本训练性能。通过这种方式,图像与文本感知的信号混合在一起,文本表示更大程度上受到视觉信息引导,从而实现更好的自适应零样本对齐。相关成果题为“CALIP: Zero-Shot Enhancement of CLIP with Parameter-free Attention”。信息学院研一学生邱龙田为该项科研成果的共同第一作者。
论文链接:https://arxiv.org/abs/2209.14169
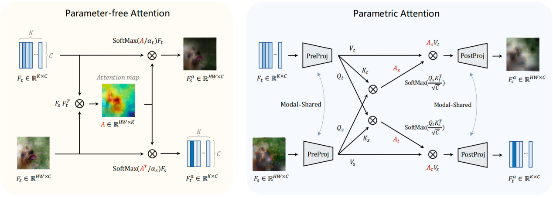
图|算法流程图
 沪公网安备 31011502006855号
沪公网安备 31011502006855号