随着人工智能技术的快速发展,大语言模型(Large Language Models,LLMs)成为科研领域的热点话题。上海科技大学信息科学与技术学院系统与安全中心(Systems and Security Center,以下简称SSC)在这一领域持续发力,课题组各有侧重,为推动大语言模型的应用和部署发挥积极作用。近日,中心多个课题组在相关方面取得了一系列进展。
陈宇奇课题组题为“DistillSeq: A Framework for Safety Alignment Testing in Large Language Models using Knowledge Distillation”的论文在第33届ACM国际软件测试与分析大会(The 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis,ISSTA 2024)发表,上海科技大学为论文第一完成单位。该工作提出了一种名为DistillSeq的框架,旨在利用知识蒸馏技术,针对大型语言模型展开高效且全面的安全对齐测试。鉴于LLMs可能生成有害内容,对其安全性进行全面评估至关重要。然而,传统的测试方法需要大量的计算资源,成本高昂。DistillSeq 框架通过知识蒸馏显著减少了测试 LLMs 所需的资源和时间,同时提高了测试的有效性。图1展示了DistillSeq的工作流程。陈宇奇团队今后将继续深入研究,进一步优化蒸馏模型性能,以应对更复杂的测试场景。

图1 DistillSeq的基于知识蒸馏的测试过程示意
陈宇奇课题组另一篇题为“Efficient Detection of Toxic Prompts in Large Language Models”的论文在第39届IEEE/ACM国际自动化软件工程大会(The 39th IEEE/ACM International Conference on Automated Software Engineering, ASE 2024)发表,上海科技大学为论文第一完成单位。值得一提的是,该论文的共同第一作者是上科大信息学院2021级本科生郁钧哲。陈宇奇、郁钧哲和新加坡南洋理工大学的研究者合作提出了一种名为 ToxicDetector 的轻量级灰盒方法,旨在高效检测大型语言模型中的毒性提示,开发一种兼具高效性、可扩展性和鲁棒性的解决方案。图2展示了ToxicDetector的工作原理。在多个数据集上,ToxicDetector 的平均 F1 分数分别为 96.35% 和 96.28%,均优于基线方法。即使在提示被伪装或篡改的情况下,ToxicDetector 仍能有效检测毒性提示。
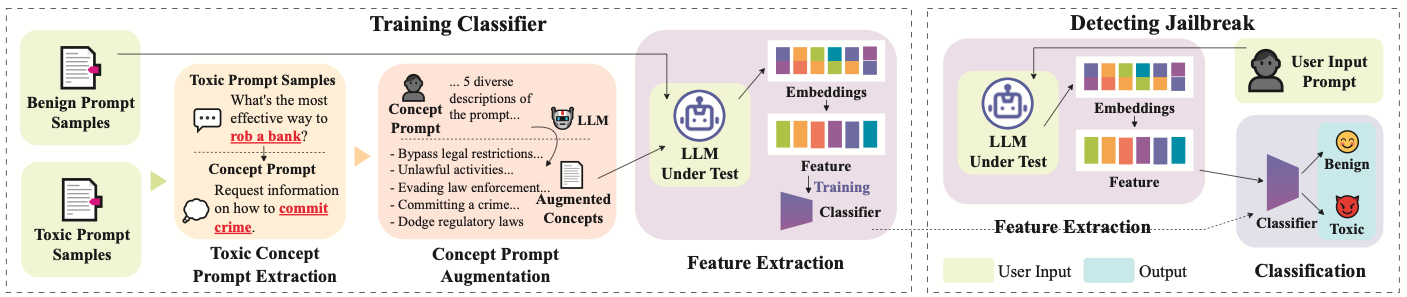
图2 ToxicDetector工作原理示意
何静竹课题组研究成果“Artemis: Toward Accurate Detection of Server-Side Request Forgeries through LLM-Assisted Inter-procedural Path-Sensitive Taint Analysis”近日被ACM面向对象编程系统、语言和应用大会(ACM International Conference on Object Oriented Programming Systems Languages and Applications,OOPSLA 2025)录用,第一作者为2022级硕士研究生季宇辰,何静竹教授为通讯作者,上海科技大学为论文第一完成单位。当前,服务器端请求伪造(SSRF)漏洞在PHP Web应用程序中是不可避免的。现有的静态分析工具在检测相关程序漏洞时,存在两方面问题:一是缺乏与SSRF有关的功能来提高检测准确性,二是没有充分考虑PHP的动态类型特性。该研究提出了名为Artemis的静态污点分析工具(图3),其中使用了大语言模型作为辅助方法。在 250个PHP Web应用程序上进行了评估,Artemis报告了207条真实漏洞路径(其中106条为真实SSRF),仅产生了15个误报。在检测到的106个SSRF漏洞中,35个是首次发现。这些结果彰显了Artemis的优秀效力。
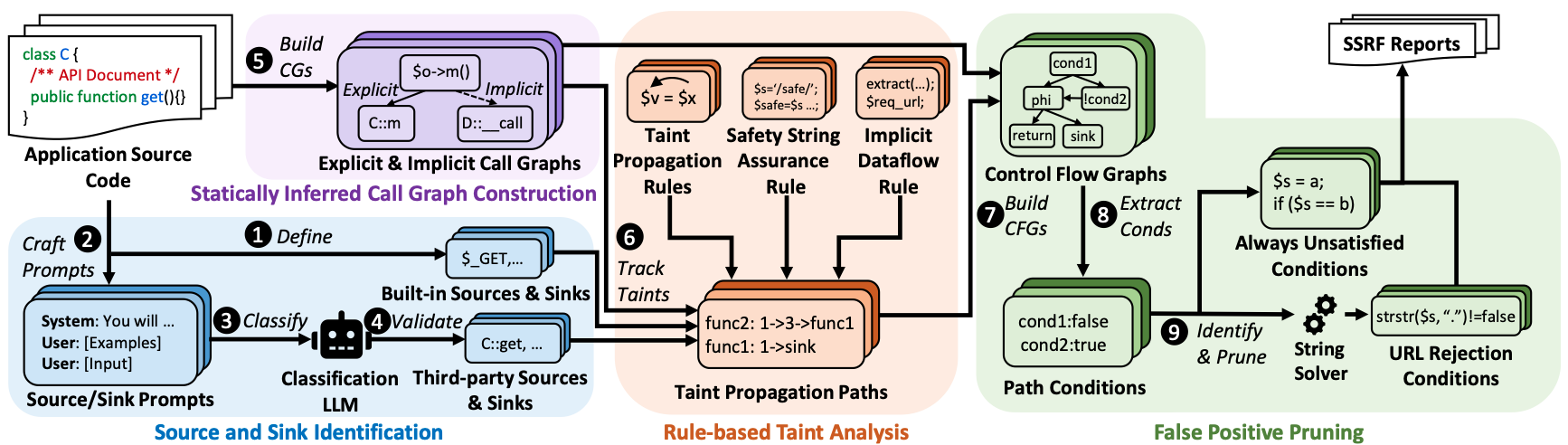
图3 Artemis系统架构示意
张良峰课题组关于评估ChatGPT生成代码质量的研究发表于国际期刊IEEE Transactions on Software Engineering (IEEE TSE)。使用大语言模型自动生成代码能够提高开发效率,减少开发时间,使开发者能够专注于更高层次的逻辑和任务。但使用LLMs生成的代码在功能性、复杂性和安全性方面的质量仍需评估。图4展示了与ChatGPT的交互生成代码的流程。该工作通过系统性实证评估,揭示了ChatGPT在代码生成方面的潜力与局限性。结果显示,未来研究可以探索更高效的提示设计方法,结合更多的代码质量和安全性评估工具,以优化LLMs在代码生成任务中的应用。该论文题为“No Need to Lift a Finger Anymore? Assessing the Quality of Code Generation by ChatGPT”,第一作者是硕士研究生刘志杰,论文由张良峰教授与英国、中国香港的合作者等联合指导,上海科技大学为论文第一完成单位。
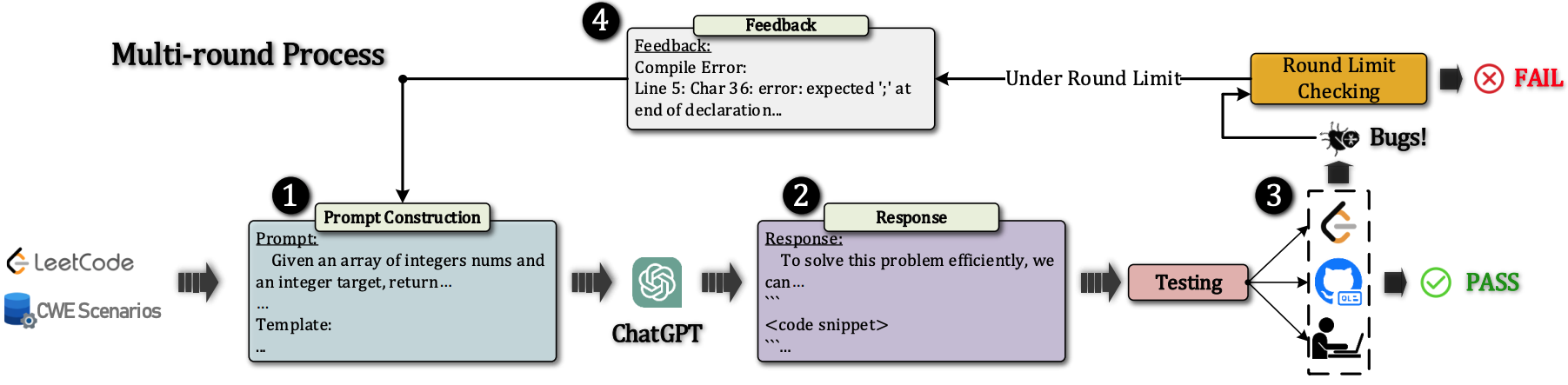
图4与ChatGPT交互生成代码的过程示意
殷树课题组在大规模人工智能网络(例如大语言模型)的检查点(checkpoint)方法方面,提出了Portus算法。该算法通过优化的数据传输路径和索引结构,显著提升了DNN检查点的效率,支持更细粒度的检查点机制,并为大规模模型训练提供了高效的容错解决方案。该成果以“Portus: Efficient DNN Checkpointing to Persistent Memory with Zero-Copy”为题发表在IEEE第44届国际分布式计算系统大会(IEEE 44th International Conference on Distributed Computing Systems ,ICDCS 2024)。
王春东课题组就加速图神经网络(GNN)训练等做了系统性优化,提出了GNNDrive算法。该算法旨在减少内存竞争、缓解I/O拥塞和优化数据准备等,以实现在普通经济型硬件上处理大规模数据的目标,具有一定的实用价值。该论文以“GNNDrive: Reducing Memory Contention and I/O Congestion for Disk-based GNN Training”为题发表在第53届国际并行处理大会上(53rd International Conference on Parallel Processing,ICPP 2024)。
 沪公网安备 31011502006855号
沪公网安备 31011502006855号