近日,上海科技大学创意与艺术学院人工智能与数字艺术实验室(AIDA)田政课题组与生物医学工程学院脑智发育实验室张寒课题组合作,在国际机器学习会议 ICLR 2026(International Conference on Learning Representations)上发表了题为“Children’s Intelligence Tests Pose Challenges for MLLMs? A 2D Grid-Based Reasoning Benchmark for MLLMs”的研究成果,提出了面向多模态大语言模型的动态交互评测基准 KidGym,为系统理解当前模型的能力边界提供了新的评测视角。

图1:KidGym基准的五维能力框架
当前,多模态大语言模型的评测大多基于静态题目或单轮问答,较难真实反映模型在持续交互、连续决策和多能力协同场景中的表现。受儿童智力测试中“能力拆解”思路的启发,研究团队结合多模态大语言模型的特点,归纳出动态交互任务中五项关键能力:执行能力、记忆能力、学习能力、规划能力和感知推理能力,并围绕这五项能力构建了KidGym。
KidGym是一个面向持续交互的动态二维网格评测环境,目前包含12类任务,每类任务设置3个难度等级,既可考察单一能力,也考察两种能力的协同。与许多静态Benchmark不同,KidGym强调模型需要在交互过程中持续观察环境、执行动作并调整决策,而不是通过一次性作答完成评测。为提高评测有效性,KidGym还引入了多样化场景、随机布局、背包、提示栏、物体编号和高层动作等机制,使评测更关注模型对能力本身的掌握,而非对已有数据模式的机械复现。KidGym 的代码架构基于 Gym API 的实现方式,也为后续任务扩展和社区复用提供了便利。

图2:KidGym基准的12项任务概览;每个子图右上角的圆形标识表示该任务涉及的核心能力维度,其中 E、M、L、P 和 PR 分别表示执行、记忆、学习、规划和感知推理能力。
实验结果表明,尽管部分前沿多模态大语言模型在某些单一能力任务上已经取得较高成功率,但在抽象或非语义视觉推理、数量判断以及多规则协同任务中仍存在明显短板,在感知推理和规划等能力维度上也整体偏弱。这说明,当前多模态大语言模型距离更稳定、更全面的通用认知能力仍有一定差距,也表明未来模型能力提升需要更加重视动态交互中的多能力整合。
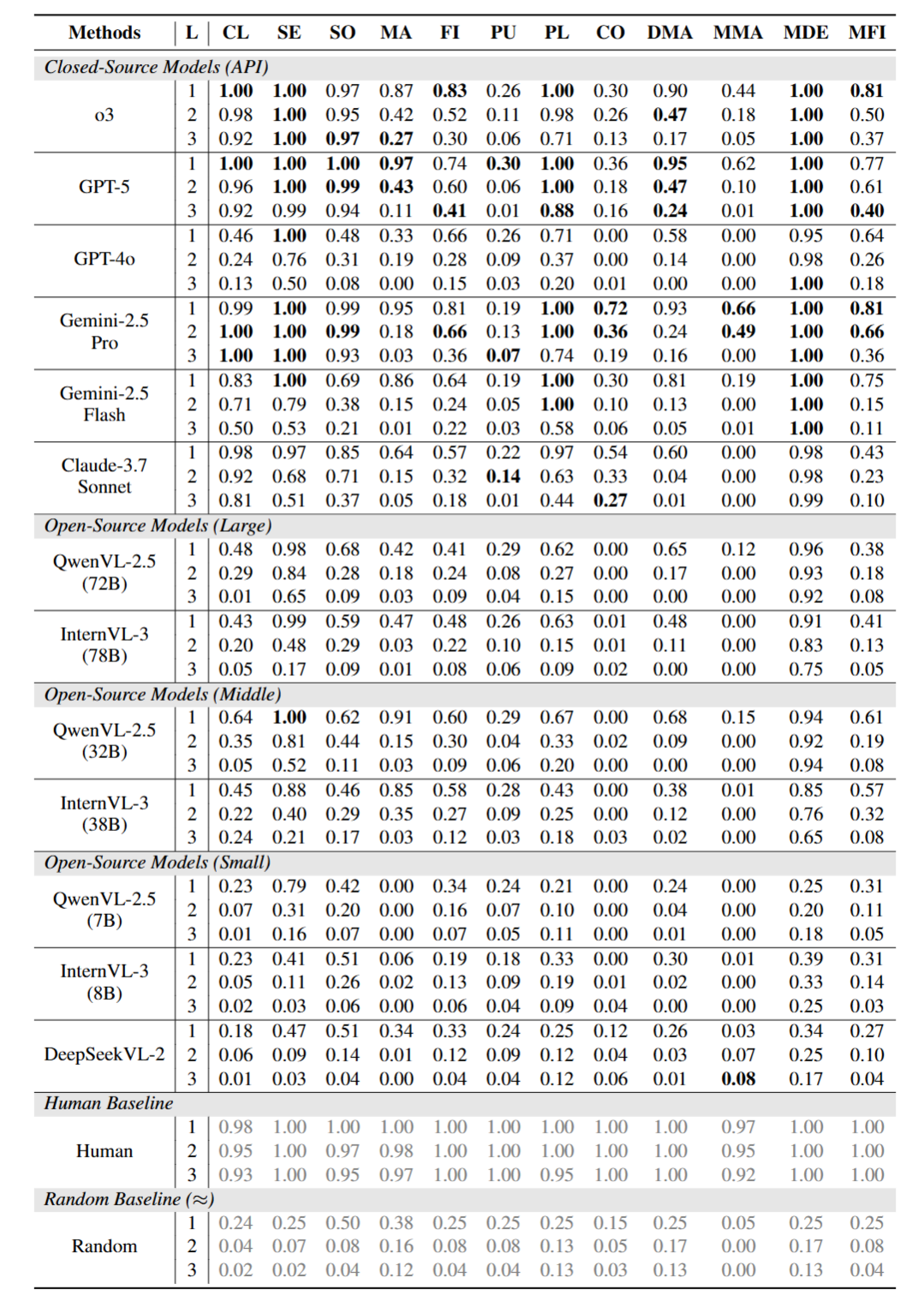
图3:当前主流多模态大语言模型在 KidGym 基准上的零样本性能比较;L 表示任务难度级别;表中结果为各模型在 100 次测试中的成功率,附带人类基线与随机基线结果以供对照。
上海科技大学为该成果第一完成单位。创意与艺术学院2024 级硕士研究生叶恒炜为论文第一作者,信息学院 2022 级本科生管垸汀为第二作者,创意与艺术学院田政教授为通讯作者。
该工作由创意与艺术学院师生共同参与完成,其中创艺学院2022 级本科生张懿靖、2023 级本科生钟奕珈参与了项目相关美术设计工作。生物医学工程学院脑智发育实验室为研究提供了儿童智力测试与认知发展方面的专业知识支持,并对基准的能力划分与任务设计提出了重要建议。
论文链接:https://arxiv.org/abs/2603.20209
 沪公网安备 31011502006855号
沪公网安备 31011502006855号